May 20, 2026
how ai learns to see
image encoders, CLIP, and self-supervised visual features
AI needs to extract meaningful features from an image.
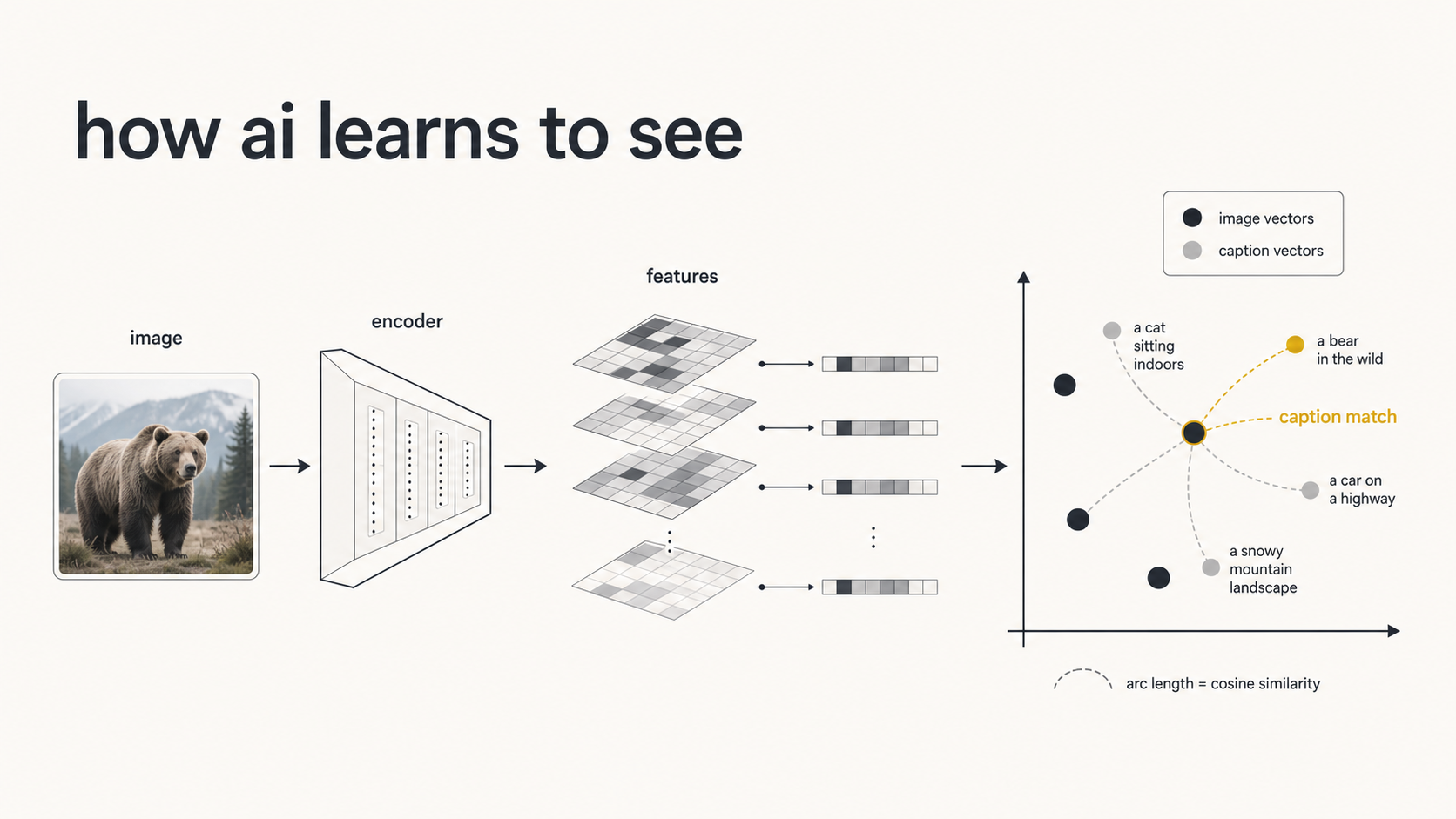
image features
A simple image classifier looks like this:
┌───────┐ ┌───────────────┐ ┌──────────┐ ┌─────────┐
│ │ │ │ │ │ │ │
│ Image ├────►│ Image encoder ├────►│ MLP head ├────►│ Softmax │
│ │ │ │ │ │ │ │
└───────┘ └───────────────┘ └──────────┘ └─────────┘open mermaid diagram
┌───────┐ ┌───────────────┐ ┌──────────┐ ┌─────────┐
│ │ │ │ │ │ │ │
│ Image ├────►│ Image encoder ├────►│ MLP head ├────►│ Softmax │
│ │ │ │ │ │ │ │
└───────┘ └───────────────┘ └──────────┘ └─────────┘For example: an image of a bear goes through the model, and the model predicts bear.
The useful part is often the encoder, not just the final label. A learned image encoder can produce feature vectors that capture the main object or visual structure in the image.
image-text alignment
Do not only describe the image directly. A text encoder can map captions into the same kind of feature space:
┌─────────┐ ┌───────────────┐ ┌────────────────┐
│ │ │ │ │ │
│ Image ├────►│ Image encoder ├────►│ Feature vector │
│ │ │ │ │ │
└─────────┘ └───────────────┘ └────────────────┘
┌─────────┐ ┌───────────────┐ ┌────────────────┐
│ │ │ │ │ │
│ Caption ├────►│ Text encoder ├────►│ Feature vector │
│ │ │ │ │ │
└─────────┘ └───────────────┘ └────────────────┘open mermaid diagram
┌─────────┐ ┌───────────────┐ ┌────────────────┐
│ │ │ │ │ │
│ Image ├────►│ Image encoder ├────►│ Feature vector │
│ │ │ │ │ │
└─────────┘ └───────────────┘ └────────────────┘
┌─────────┐ ┌───────────────┐ ┌────────────────┐
│ │ │ │ │ │
│ Caption ├────►│ Text encoder ├────►│ Feature vector │
│ │ │ │ │ │
└─────────┘ └───────────────┘ └────────────────┘The goal is for matching image and text vectors to be close together. A common way to measure that is cosine similarity.
If the image and caption match, their vectors should be close. If they do not match, their vectors should be far apart.
This is the core idea behind Contrastive Language-Image Pretraining, or CLIP.
self-supervised vision
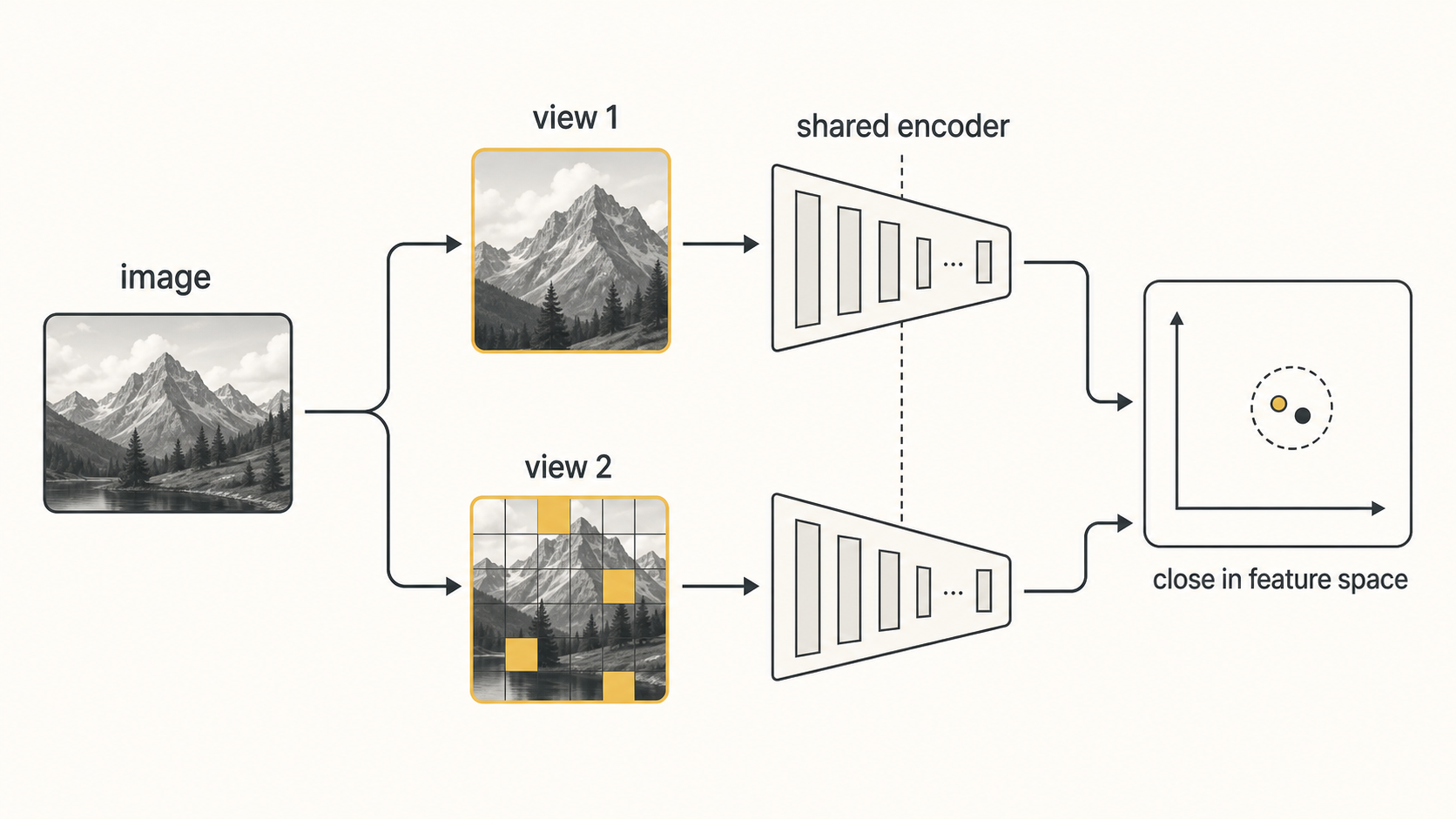
CLIP still needs image-text pairs. Self-supervised learning tries to learn useful visual features without manual labels.
The training task can come from the image itself: rotation, inpainting, masking, or comparing different views of the same image.
In contrastive image learning, two crops or augmentations of the same image should land near each other in feature space.
┌───────┐ ┌────────┐ ┌─────────┐ ┌───────────────┐
│ │ │ │ │ │ │ │
│ Image ├────►│ View 1 ├────►│ Encoder ├─close►│ Feature space │
│ │ │ │ │ │ │ │
└───┬───┘ └────────┘ └─────────┘ └───────────────┘
│ ▲
│ │
│ │
│ │
│ │
│ ┌────────┐ ┌─────────┐ close
│ │ │ │ │ │
└────────►│ View 2 ├────►│ Encoder ├───────────────┘
│ │ │ │
└────────┘ └─────────┘ open mermaid diagram
┌───────┐ ┌────────┐ ┌─────────┐ ┌───────────────┐
│ │ │ │ │ │ │ │
│ Image ├────►│ View 1 ├────►│ Encoder ├─close►│ Feature space │
│ │ │ │ │ │ │ │
└───┬───┘ └────────┘ └─────────┘ └───────────────┘
│ ▲
│ │
│ │
│ │
│ │
│ ┌────────┐ ┌─────────┐ close
│ │ │ │ │ │
└────────►│ View 2 ├────►│ Encoder ├───────────────┘
│ │ │ │
└────────┘ └─────────┘ That way, the model learns visual structure from the data itself.